Safe and trustworthy thought partners
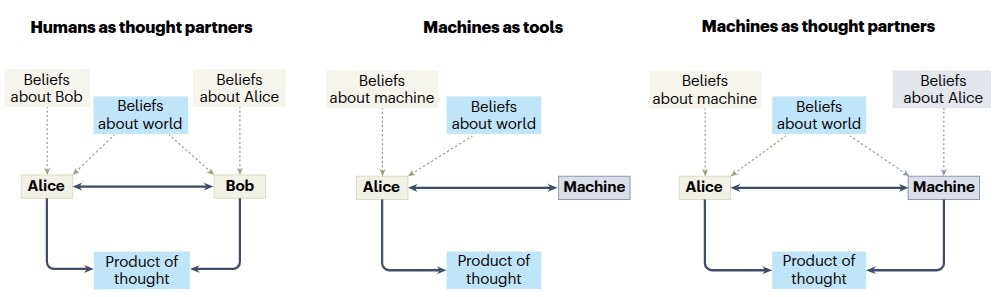
Partnership has failure modes: bias, overreliance, manipulation, de-skilling, miscalibrated trust, and metacognitive blindness. We pursue three complementary directions: (1) diagnosing failures (measurement and taxonomy), (2) understanding how humans calibrate trust and decide when to defer to AI, and (3) engineering integrity through interventions and end-to-end systems.
Representative work. Identifying, Evaluating, and Mitigating Risks of AI Thought Partnerships (Oktar et al. 2025) frames the risk landscape. Measuring and Mitigating Overreliance (Ibrahim et al. 2025) makes the case for an integrated research program. Modulating Language Model Experiences through Frictions studies interventions for safer LLM use. Dimensions of Disagreement (Oktar et al., Decision 2025) maps when and how humans trust noisy advisors. Under the Influence: Quantifying Persuasion and Vigilance in LLMs (Robinson et al. 2026) characterizes how language models persuade and are persuaded.
Funding context. This program anchors the lab’s DARPA “In the Moment” (ITM) involvement (Algorithmic Trust at Scale, co-PI; 2025 to 2027).