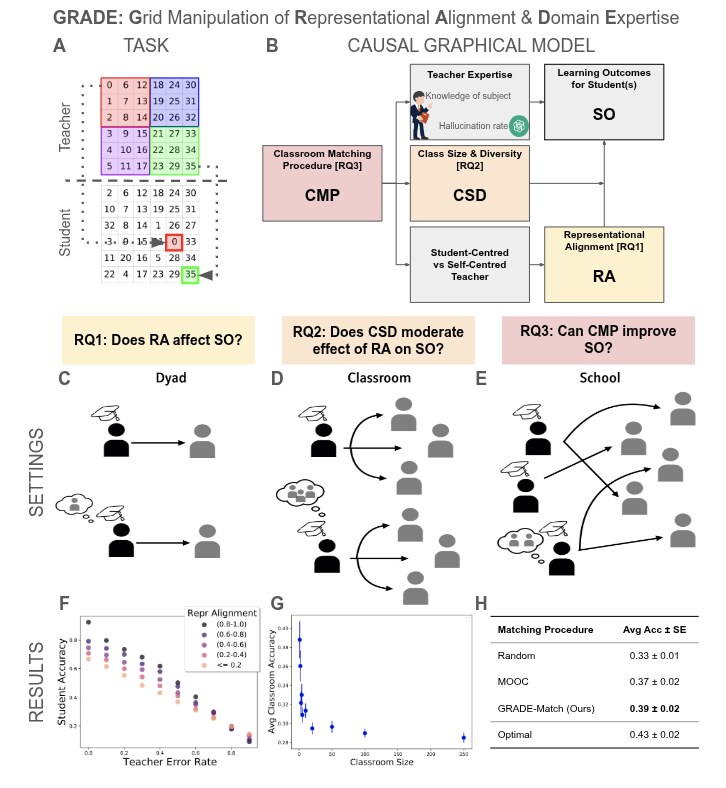
Alignment between human and AI minds
How human and AI minds come to share structure, and how to measure, teach, and improve that alignment.
Read moreShow less
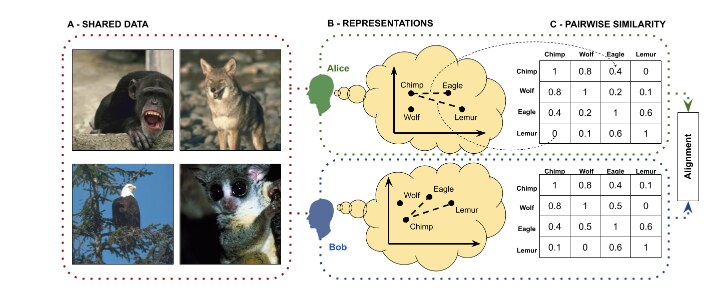
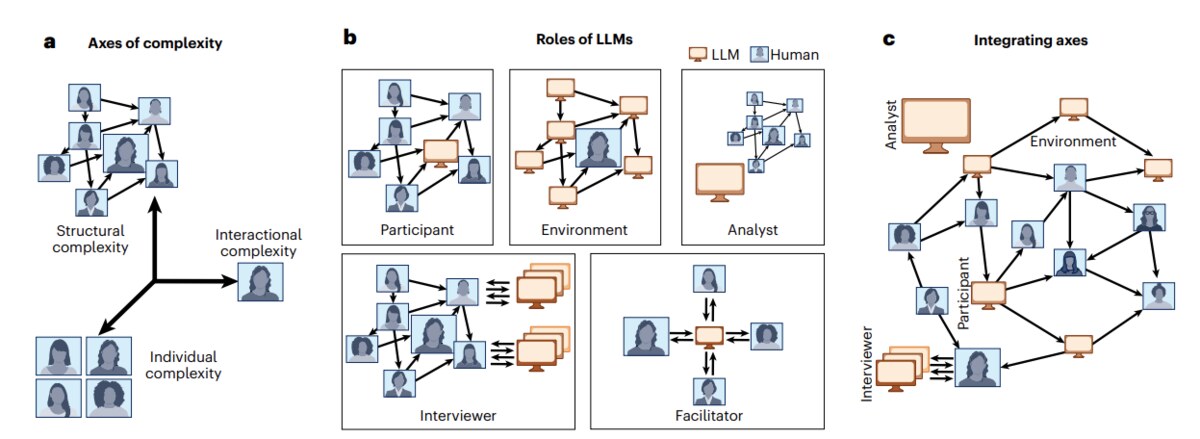
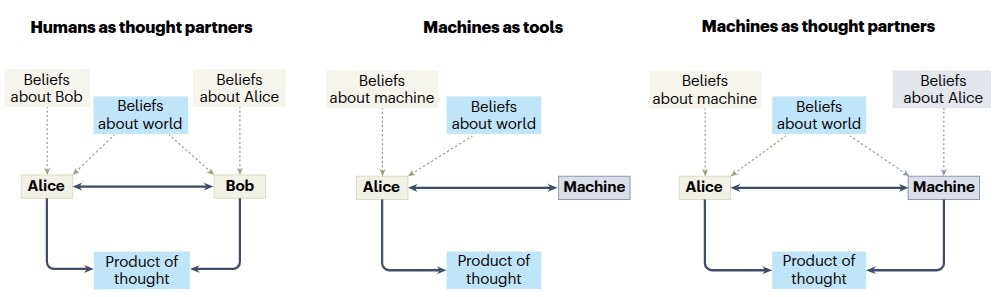
The lab’s theoretical anchor. We study how minds, biological and artificial, come to share structure across representations, concepts, values, and perception, and we use that structure as a tool to make AI systems more compatible with people.
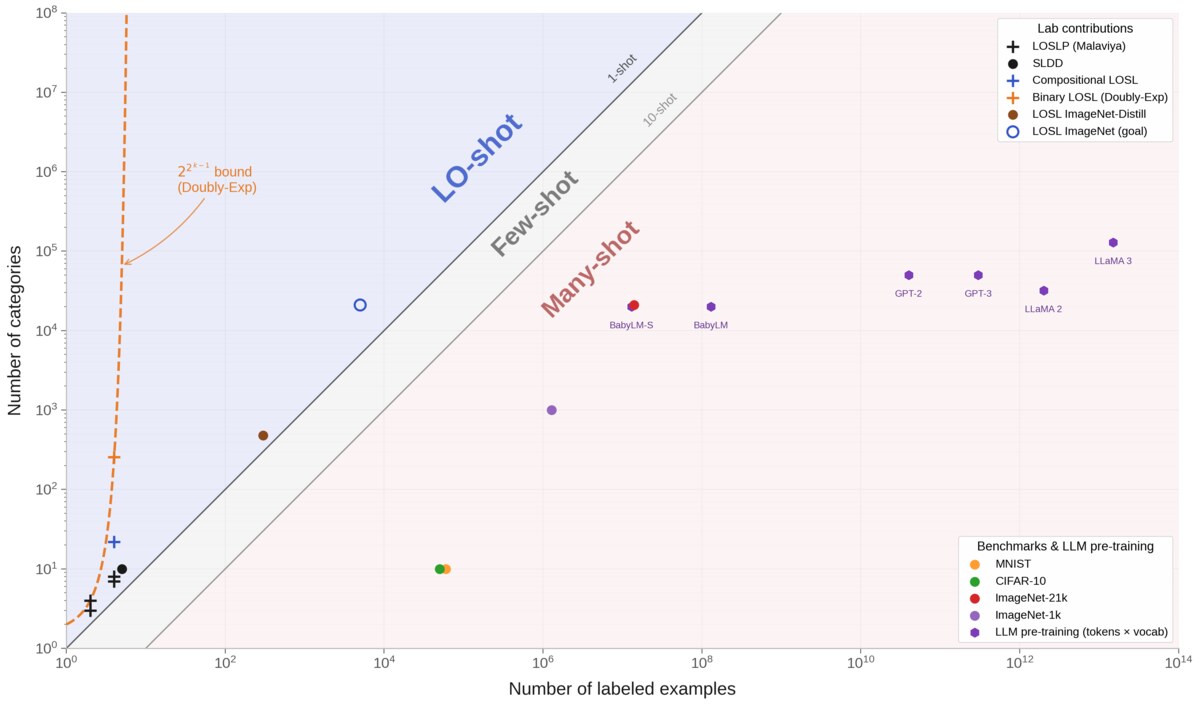
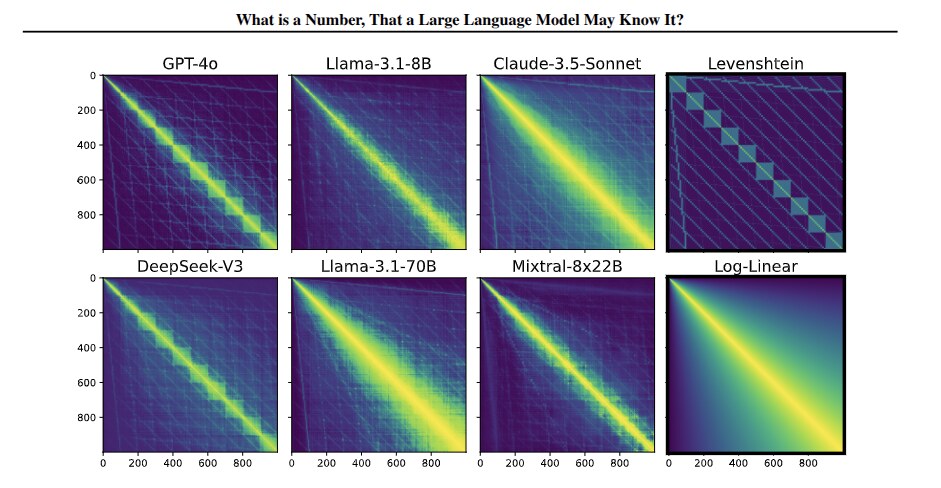
Representative work. Alignment with human representations supports robust few-shot learning (NeurIPS 2023 Spotlight) shows a U-shaped relationship between human-model representational alignment and downstream task performance. Getting aligned on representational alignment (TMLR 2025) lays out a community-wide research agenda for the field. On the informativeness of supervision signals (UAI 2023 Spotlight) develops the information-theoretic backbone connecting soft-label supervision to alignment.