Data-efficient learning (LO-shot)
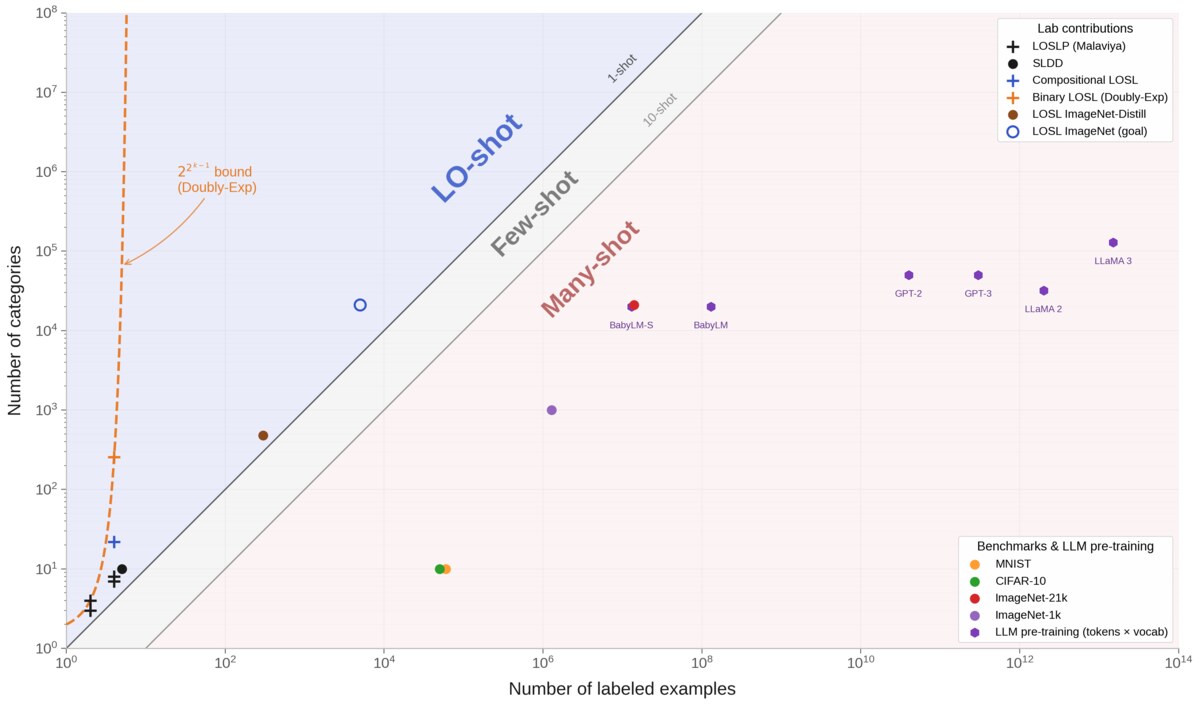
A multi-year program on the fundamental limits of learning from very few examples. We introduced less-than-one-shot (LO-shot) learning, the regime where a learner extracts more categories from a training set than there are examples in it. The program maps the theory, the human counterpart, and the implications for AI training.
Representative work. ‘Less Than One’-Shot Learning (AAAI 2021) launched the program. Soft-label dataset distillation (IJCNN 2021 Oral) develops the training-time mechanism. Using compositionality to learn many categories from few examples (CogSci 2024) extends to compositional concept structure. Learning a doubly-exponential number of concepts from few examples (CogSci 2025) pushes the theoretical ceiling further.